Vulkan vs CUDA on NVIDIA Blackwell: The Benchmark Nobody Expected
Tested on RTX PRO 6000 Blackwell Server Edition (96 GB VRAM) with llama.cpp b7966, February 2026
TL;DR
We benchmarked 8 LLM models (1B to 70B parameters) across two backends, two operating systems, and six runs. Vulkan with coopmat2 challenged CUDA 13.1 on NVIDIA's newest architecture. The results broke every assumption we had.
The headlines:
- 8B and smaller : use CUDA. It dominates prompt processing and throughput on small models.
- 32B and above : try Vulkan. Token generation is 18 to 41% faster. The speed you feel during inference.
- Mistral Nemo 12B : use Vulkan, no question. 8.3x faster than CUDA (not a typo).
- Thermal behavior differs by backend. CUDA thermal-throttled gracefully at 95°C. Vulkan crashed with unrecoverable device-lost errors instead.
- Server GPUs should stay in server cases. A 600W passive GPU in a consumer mid-tower is a recipe for thermal disaster.
- OS choice barely matters. Linux and Windows CUDA performance within 5 to 10%.
The Setup

| Component | Detail |
|---|---|
| GPU | NVIDIA RTX PRO 6000 Blackwell Server Edition, 96 GB VRAM |
| CPU | AMD Ryzen 7 9800X3D |
| RAM | 60 GB DDR5 |
| OS | openSUSE Linux 6.18 + Windows 11 pro (same hardware) |
| Engine | llama.cpp b7966 (Vulkan with NV_coopmat2, CUDA 13.1) |
| Benchmark | localscore-bench: 3 configs per model (see below) |
The Methodology
- Engine: llama.cpp b7966 (same commit for both backends)
- Vulkan backend: ggml-org/llama.cpp releases, with NV_coopmat2 cooperative matrix support
- CUDA backend: ai-dock/llama.cpp-cuda releases, CUDA 13.1
- Test suite: Quick mode with 3 configurations that simulate real-world usage patterns:
- pp1024+tg16: Process a long prompt (1024 tokens), generate a short answer (16 tokens). Measures prompt processing speed. Think summarization, RAG retrieval, or classification tasks.
- pp1024+tg1024: Process a long prompt, generate a long response. Balanced workload. Think chatbot conversations or document Q&A.
- pp16+tg1536: Process a short prompt (16 tokens), generate a very long response. Stresses sustained token generation. Think creative writing, code generation, or long-form content.
- Inspiration: Test methodology adapted from localscore , a practical benchmark for local LLM inference
- GPU monitoring: nvidia-smi at 200ms intervals, capturing utilization, power, temperature, and VRAM
- Quantization: Q4_K_M for all models (4-bit, medium quality)
- Runs: 4 complete runs on Linux (plus 1 aborted), 7 runs on Windows (4 with valid GPU access)
- All results and raw data: github.com/bauagonzo/llm-bench-lab
The Results
Linux: Vulkan vs CUDA
| Model | Params | Vulkan PP | Vulkan TG | CUDA PP | CUDA TG | Winner |
|---|---|---|---|---|---|---|
| Gemma 3 1B | 1.0B | 3,390 | 61 | 28,712 | 539 | CUDA |
| Llama 3.2 1B | 1.2B | 3,526 | 117 | 31,091 | 785 | CUDA |
| Phi-4 Mini | 3.8B | 1,315 | 45 | 14,681 | 334 | CUDA |
| Ministral 8B | 8.0B | 652 | 29 | 8,458 | 208 | CUDA |
| Gemma 3 12B | 11.8B | 5,341 | 117 | 5,708 | 123 | CUDA |
| Mistral Nemo 12B | 12.2B | 4,776 | 51 | 577 | 25 | Vulkan 8.3x |
| Qwen3 32B | 32.8B | 1,956 | 58 | 2,221 | 41 | Split |
| Llama 3.3 70B | 70.6B | 1,394 | 30 | 1,613 | 25 | Split |
PP = Prompt Processing (tokens/sec). TG = Token Generation (tokens/sec).
Vulkan PP numbers on small models (1B-8B) are significantly lower than CUDA.
This likely reflects the maturity gap in Vulkan's prompt processing kernels, which are not yet optimized for small batch sizes on Blackwell.
Finding 1: The Mistral Nemo Anomaly
This finding made us recheck our methodology three times.
Mistral Nemo 12B on CUDA: 577 t/s prompt processing, 25 t/s generation.
Mistral Nemo 12B on Vulkan: 4,776 t/s prompt processing, 51 t/s generation.
That is an 8.3x gap in prompt processing. Same GPU. Same model. Same llama.cpp build.
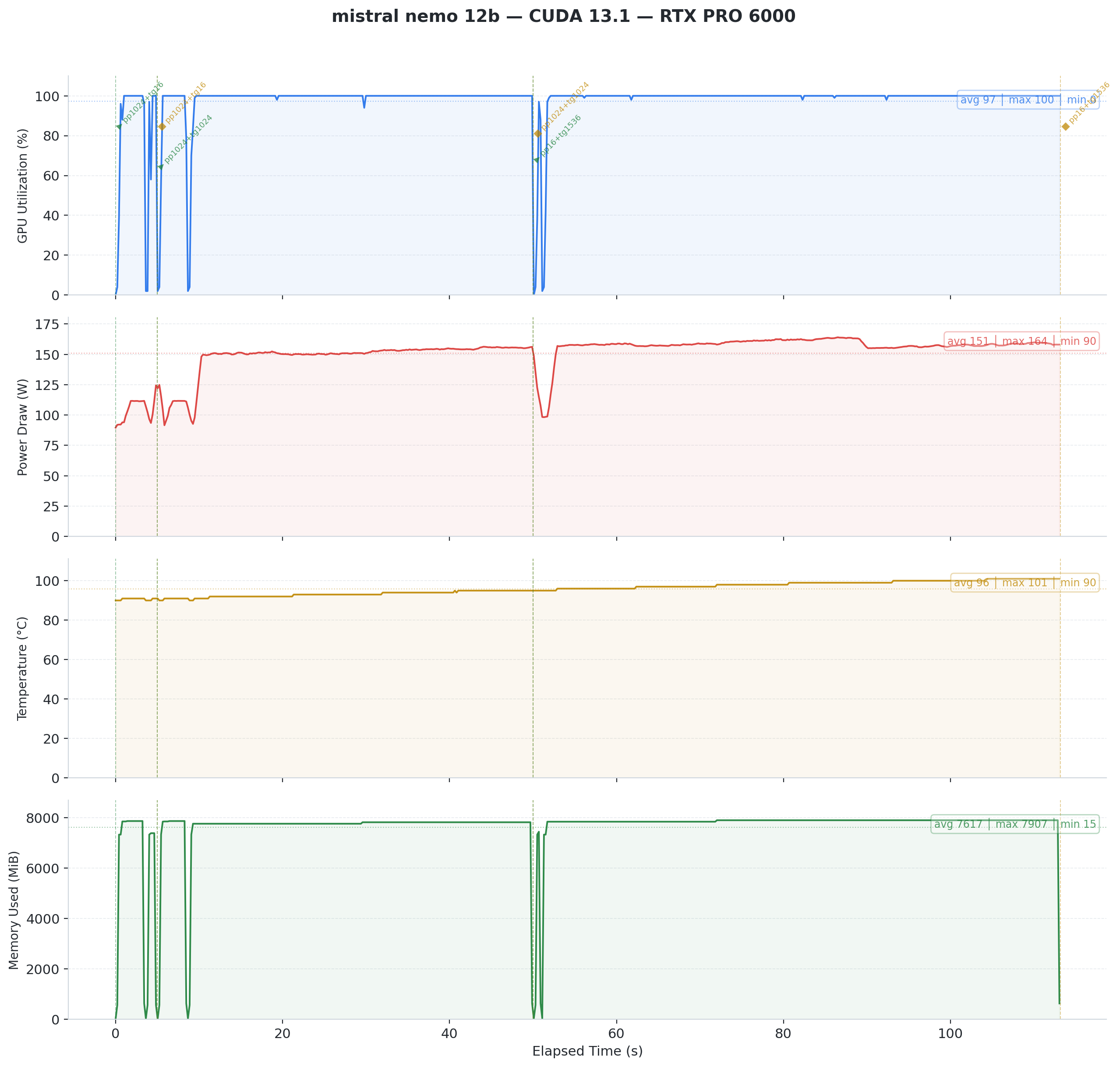 Fig 1: Mistral Nemo 12B on CUDA 13.1. GPU utilization reports 97% average, but power draw tells a different story. The GPU never exceeds 164W on a 600W TDP card. Something is wrong.
Fig 1: Mistral Nemo 12B on CUDA 13.1. GPU utilization reports 97% average, but power draw tells a different story. The GPU never exceeds 164W on a 600W TDP card. Something is wrong.
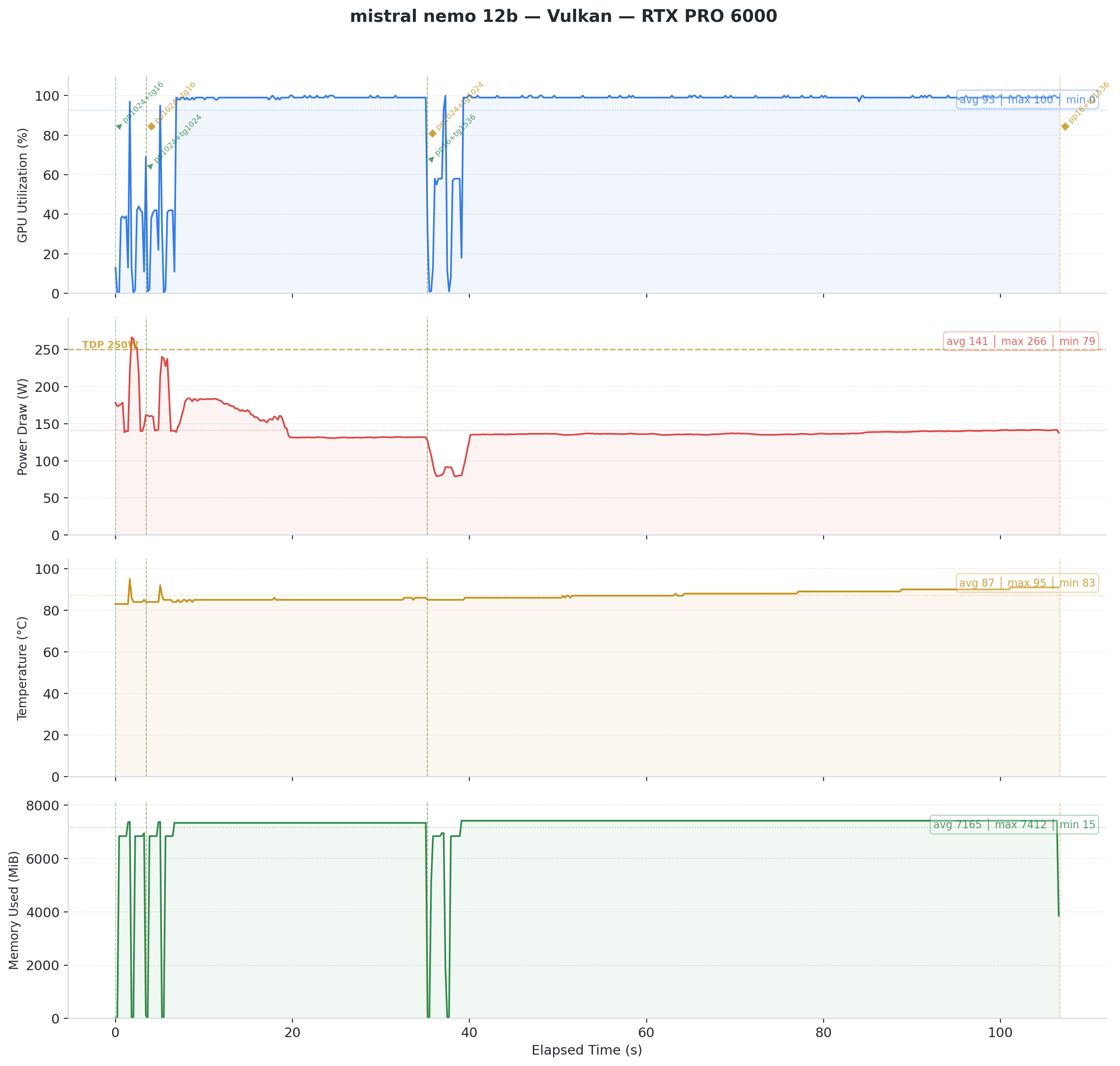 Fig 2: Mistral Nemo 12B on Vulkan. Same model, same GPU, completely different behavior. Power peaks at 266W. The GPU works for real this time.
Fig 2: Mistral Nemo 12B on Vulkan. Same model, same GPU, completely different behavior. Power peaks at 266W. The GPU works for real this time.
Under CUDA, the card reports high utilization but draws minimal power. It sits mostly idle despite what nvidia-smi claims. Under Vulkan, power draw matches actual computation.
Our theory: CUDA's Blackwell kernels hit a suboptimal code path for Mistral Nemo's layer dimensions. This looks like a bug, not a fundamental limitation. The anomaly persists across all runs (Feb 9, Feb 11, Feb 12) and on Windows. It is deterministic and reproducible.
Why this matters: If you run Mistral Nemo 12B on Blackwell hardware, switching from CUDA to Vulkan gives you a free 8x speedup. No hardware change required.
Finding 2: Token Generation Crosses Back to Vulkan at 32B+
We expected a clean pattern: Vulkan wins small, CUDA wins big. The data refused to cooperate.
For prompt processing, CUDA's advantage grows with model size. No surprises there. But for token generation (the speed you feel during inference), the story reverses above 32B:
| Model | Vulkan TG | CUDA TG | Delta |
|---|---|---|---|
| Ministral 8B | 29 | 35 | CUDA +19% |
| Gemma 3 12B | 117 | 123 | CUDA +6% |
| Qwen3 32B | 58 | 41 | Vulkan +41% |
| Llama 3.3 70B | 30 | 25 | Vulkan +18% |
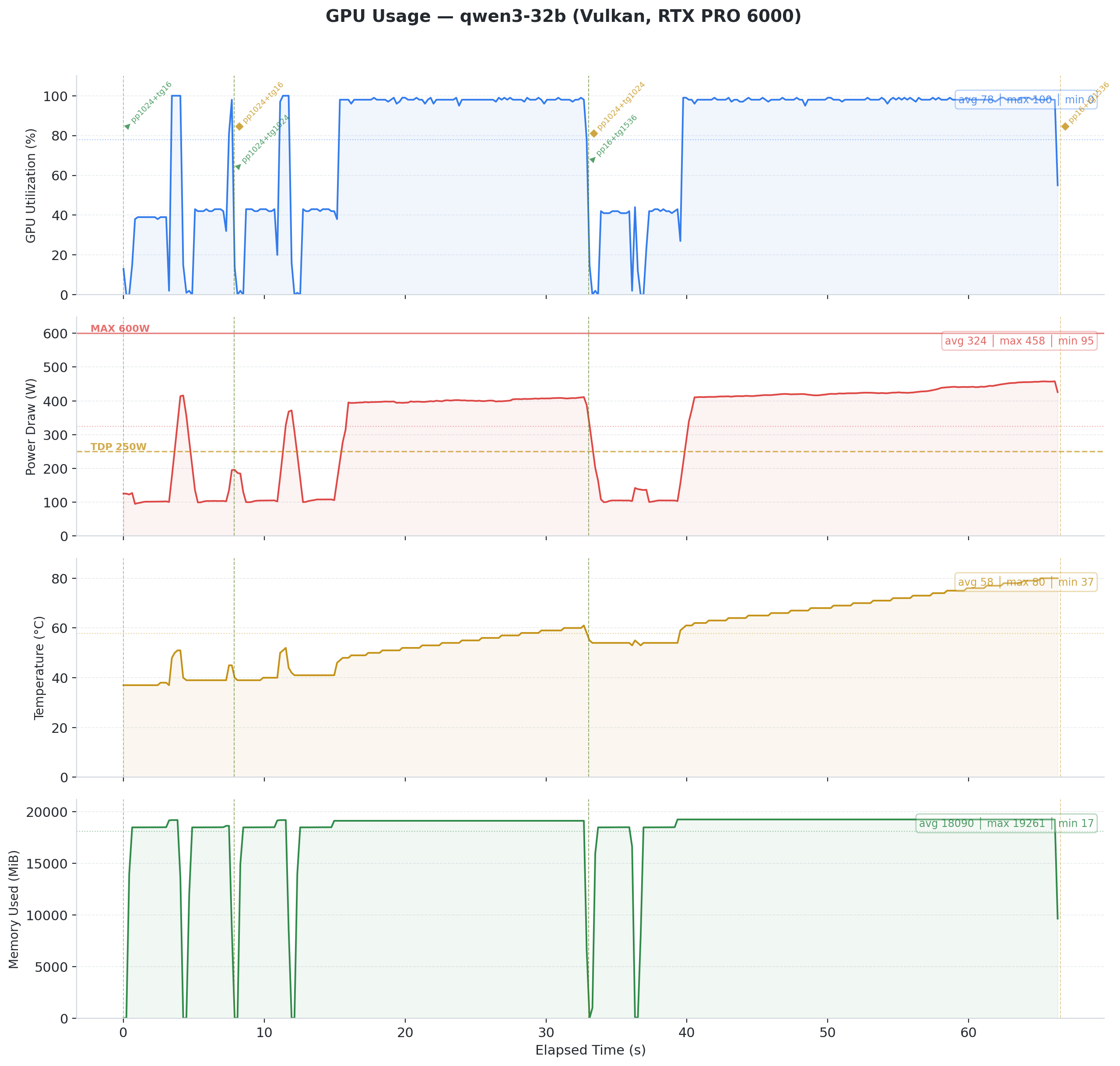 Fig 3: Qwen3 32B on Vulkan. Steady 400W power draw, temperature climbing from 37C to 80C. Token generation holds at ~58 t/s throughout.
Fig 3: Qwen3 32B on Vulkan. Steady 400W power draw, temperature climbing from 37C to 80C. Token generation holds at ~58 t/s throughout.
The takeaway: For 32B+ models in interactive use (chatbots, coding assistants), Vulkan delivers faster responses. The 41% advantage on Qwen3 32B translates to noticeably snappier inference.
Finding 3: CUDA Thermal Throttling Under Sustained Load
The Qwen3 32B CUDA run exposed a thermal problem. The benchmark runs three configurations:
- pp1024+tg16 (short burst): 52 t/s TG
- pp1024+tg1024 (medium run): 52 t/s TG
- pp16+tg1536 (long generation): 11.6 t/s TG
That is a 4.5x performance cliff within a single benchmark session. Temperature climbed to 95C. NVIDIA's thermal management aggressively downclocked the GPU, dropping power from ~500W to ~150W.
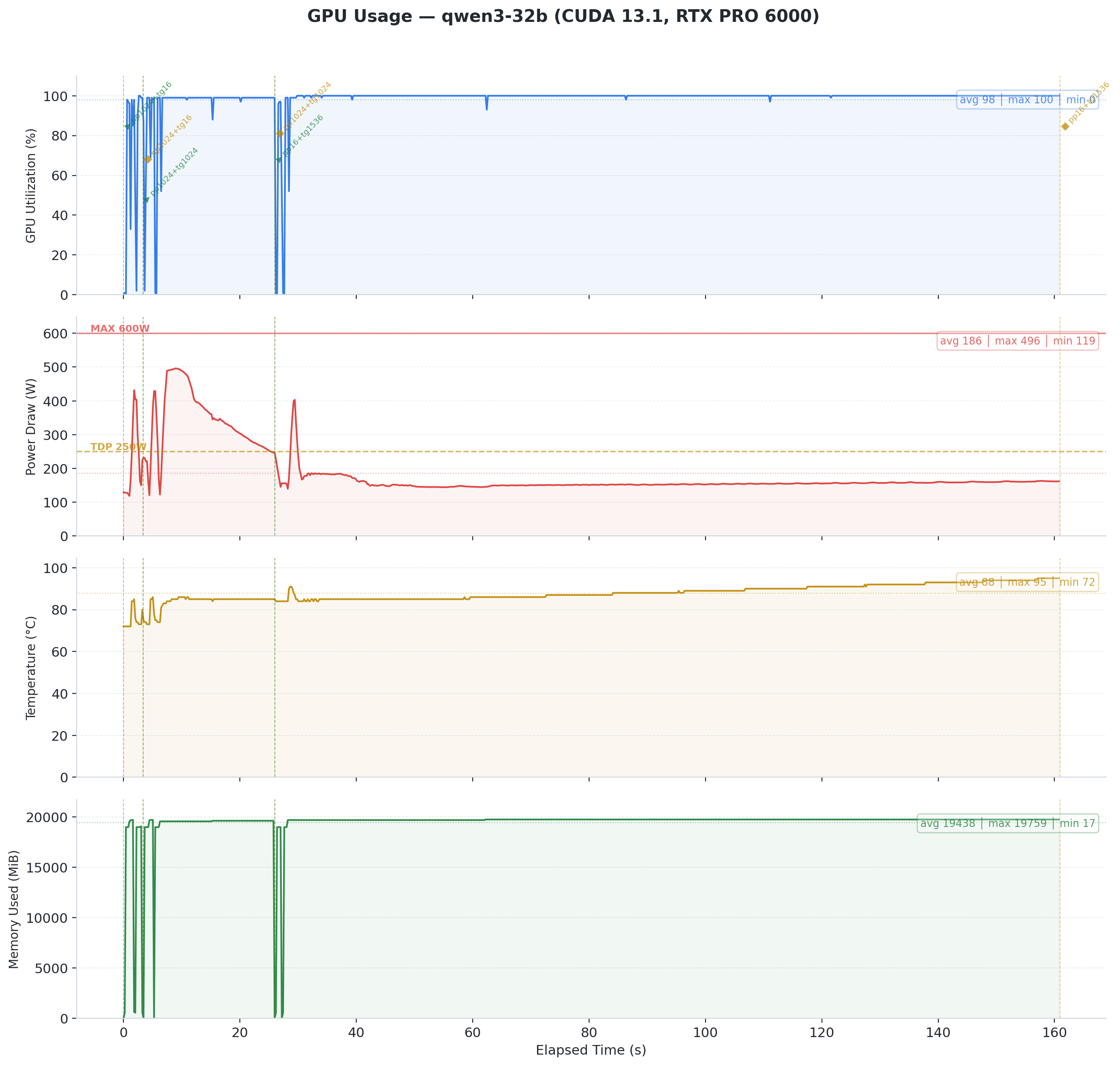 Fig 4: Qwen3 32B on CUDA 13.1. Power spikes to ~500W during the initial burst, then collapses to ~150W as temperature hits 95C. GPU utilization stays at 100% throughout, but the driver downclocks aggressively to survive. This is thermal throttling in action.
Fig 4: Qwen3 32B on CUDA 13.1. Power spikes to ~500W during the initial burst, then collapses to ~150W as temperature hits 95C. GPU utilization stays at 100% throughout, but the driver downclocks aggressively to survive. This is thermal throttling in action.
Vulkan avoided this on the same model. It ran at lower average power (324W vs CUDA's initial 500W burst). CUDA's compute kernels appear to push the GPU harder upfront, drawing peak power before thermals catch up. Vulkan's coopmat2 path spreads the work more evenly, staying within our cooling budget. The result is the same computation at sustainable power levels.
Across all testing, we recorded six GPU crashes : four from Vulkan, two from CUDA. CUDA throttled gracefully under thermal pressure. The driver downclocked the GPU and the workload continued at reduced performance. Vulkan workloads did not get that chance. They triggered VK_ERROR_DEVICE_LOST at the PCIe level, an unrecoverable error that required a full power cycle every time.
Finding 4: The Real Bottleneck Was Never the Backend
Here is the twist that reframes everything above. Our crashes, thermal throttling, and performance cliffs share a common root cause. It is not Vulkan. It is not CUDA. It is cooling.
A Passive GPU in a Consumer Case
The RTX PRO 6000 Blackwell Server Edition has no fans. Run nvidia-smi and Fan Speed reads N/A. This card draws up to 600W TDP (configurable from 300W to 600W).
NVIDIA designed it for rack servers like the Dell PowerEdge XE9680 and R760xa , where engineered front-to-back airflow tunnels force high-pressure air through the heatsink fins.
The Central Computer overview and VAST AI comparison both stress this point : the Server Edition requires external chassis airflow. No exceptions.
We put this card in an Antec C5 mid-tower case. Seven Antec P12 120mm ARGB fans provide airflow : six reversed as intake (bottom and side panels) and one rear exhaust. The case uses a vertical bottom-to-top airflow scheme.
Each P12 pushes roughly 50 to 60 CFM at 1.5 to 2.0 mm H2O static pressure. Total theoretical intake : about 330 CFM.
That sounds like plenty. It is not !
Why 330 CFM Falls Short
Three problems turn 330 CFM into a fraction of what the GPU needs.
Direction. The P12 fans push air vertically and from the side. The GPU heatsink fins run front to back. Air flows around the card, not through it. Without baffles or ducting, the path of least resistance bypasses the heatsink entirely.
Static pressure. Dense passive heatsink fins need 5 to 10+ mm H2O of static pressure to force air through them. The P12 fans deliver 1.5 to 2.0 mm H2O. Consumer case fans cannot push through server-grade fin density.
No ducting. Nothing seals the airflow path. Hot air recirculates. Cold air takes shortcuts. The GPU sits in a pocket of turbulence, not a cooling tunnel.
Realistic estimate: only 30 to 40% of total chassis airflow actually passes through the GPU heatsink. That puts effective GPU airflow at roughly 100 to 130 CFM.
The Math Says We Are at the Edge
A standard electronic cooling formula gives the required airflow through a heat source:
CFM = (Watts x 3.16) / Delta T (degrees C)
For our 600W card:
| Allowed Air Temp Rise | Required CFM Through Card |
|---|---|
| 10 degrees C | ~190 CFM |
| 15 degrees C | ~125 CFM |
Our estimated 100 to 130 CFM sits right at the boundary for a 15 degree C rise. Any sustained load that pushes power above 400W will exceed what our airflow can dissipate. The GPU temperature climbs until thermal protection kicks in.
Community Results Confirm the Problem
Other builders on r/LocalLLM tested the same card in non-server enclosures. Their results match our analysis:
| Fan Setup | CFM (Directed) | Idle Temp | Load Temp | Verdict |
|---|---|---|---|---|
| Thermalright TY-143 (single) | ~130 | 50 C | 85 C | Marginal, throttles under sustained load |
| Wathai 120x38mm server fan + custom duct | ~220 | 33 C | 61-62 C | Stable, no throttling |
The difference is not raw CFM. It is directed, high-pressure airflow through the heatsink with proper ducting. The Wathai setup uses a server-grade fan (high static pressure) mounted in a custom shroud that forces every cubic foot of air through the card.
Finding 5: Cross-OS Comparison Shows Minimal Difference
The bottom line: OS choice barely matters. We ran the full suite on Windows (same hardware, driver 582.32) on February 11. Small to medium models performed within 5 to 10% across operating systems. Linux holds a slight edge, but the difference is negligible for practical use.
| Model | Linux CUDA PP | Windows CUDA PP | Linux CUDA TG | Windows CUDA TG |
|---|---|---|---|---|
| Gemma 3 1B | 28,712 | 27,952 | 539 | 517 |
| Llama 3.2 1B | 31,091 | 30,764 | 785 | 774 |
| Phi-4 Mini 3.8B | 14,681 | 14,631 | 334 | 320 |
| Ministral 8B | 8,458 | 7,767 | 208 | 171 |
| Qwen3 32B | 2,221 | 2,202 | 41 | 59 |
| Llama 3.3 70B | Crash (run 3) | CPU fallback | N/A | 1.2 |
This is good news. Pick the OS you prefer ! Performance follows the hardware, not the operating system.
Qwen3 32B produced valid Windows results (2,202 PP, 59 TG) that closely match Linux Vulkan numbers.
Llama 3.3 70B failed on both platforms, confirming that the 70B stability issue is hardware-level, not OS-specific.
The Mistral Nemo CUDA anomaly also persists on Windows (575 PP vs Vulkan's 4,776 PP), confirming an architecture-level issue.
Don't Do This at Home
We ran a 600W passive server GPU in a consumer mid-tower case. This is a terrible idea. The RTX PRO 6000 Server Edition has zero fans. NVIDIA designed it for rack servers with engineered front-to-back airflow tunnels.
What went wrong: thermal throttling, performance cliffs, and GPU crashes. Our seven case fans delivered roughly 330 CFM total, but only 100 to 130 CFM actually reached the heatsink. That is not enough for sustained 400W+ loads.
If you insist on doing it anyway, you need:
- Server-grade fans (e.g., Wathai 120x38mm) with 5 to 10+ mm H2O static pressure
- Custom ducting or shroud that forces air through the heatsink, not around it
- Temperature monitoring with automatic shutdown at 95C
- A PSU rated for 850W+ to handle peak GPU draw plus the rest of your system
- Baffles or seals to prevent hot air recirculation
The r/LocalLLM community proved it works with the right setup: a server fan plus custom duct held load temps at 61C. Consumer case fans alone hit 85C and throttled.
What Comes Next
The Blackwell architecture is new. Drivers change fast. Our next steps:
- Driver bisection: Pin down which CUDA driver update caused the small-model speedup
- RTX 5090 Ti comparison: Same test suite on consumer Blackwell silicon
- Flash Attention investigation: Determine whether the Feb 12 CUDA boost relates to Flash Attention enablement
We will publish updates in the same repository as results come in.
Raw data, scripts, and GPU monitoring charts available at github.com/bauagonzo/llm-bench-lab .